原文链接:VAGEN github
简介
RICO的概念
针对 LLM agents 的强化学习框架取得了显著进展,其中包括 RAGEN、Search-R1、Agent-R1 和 OpenManus-RL 等。这些框架通常采用Reason-Interaction Chain Optimization (RICO) 方法来训练 LLM。
RICO 的核心思想是将多轮 agent 与环境的互动轨迹视为一个统一的token序列进行处理。它将完整的互动轨迹作为一个单一序列进行端到端训练,奖励会反向传播给所有 token,平等地对待每一个token。
RICO的局限性
尽管RICO对LLM agents是有效的,但在VLM agents的训练中效率很低。这可能是由于:
- 分布偏移 (Distribution Shift):大多数 VLM 在预训练时并未训练生成图像 token。当RICO 引入多模态输出时(尽管此处主要指文本输出中的思考和行动 token,但 VLM agents 需要处理视觉输入),会造成分布偏移。
- 状态冗余 (State Redundancy):视觉任务往往包含大量状态冗余,例如长上下文图像和过多的低级细节。这削弱了 RICO 的状态学习目标效率。
TRICO的提出
为了解决这些挑战,作者引入了VAGEN,即一个用于训练 VLM Agents 的多轮 RL 框架。其核心是Turn-aware Reason-Interaction Chain Optimization (TRICO) 算法。TRICO在RICO基础上增加了两个创新:
- 选择性Token 掩码 (Selective Token Masking):TRICO 引入两种掩码机制,将优化重点放在交互轮次中的行动关键 token (action-critical tokens) 上
- 跨轮次信用分配 (Cross-turn Credit Assignment):TRICO 使用不同的折扣因子计算跨轮次和轮次内的优势,并采用轮次级别的奖励,从而在多轮视觉 agentic 任务中实现更有效的信用分配

方法
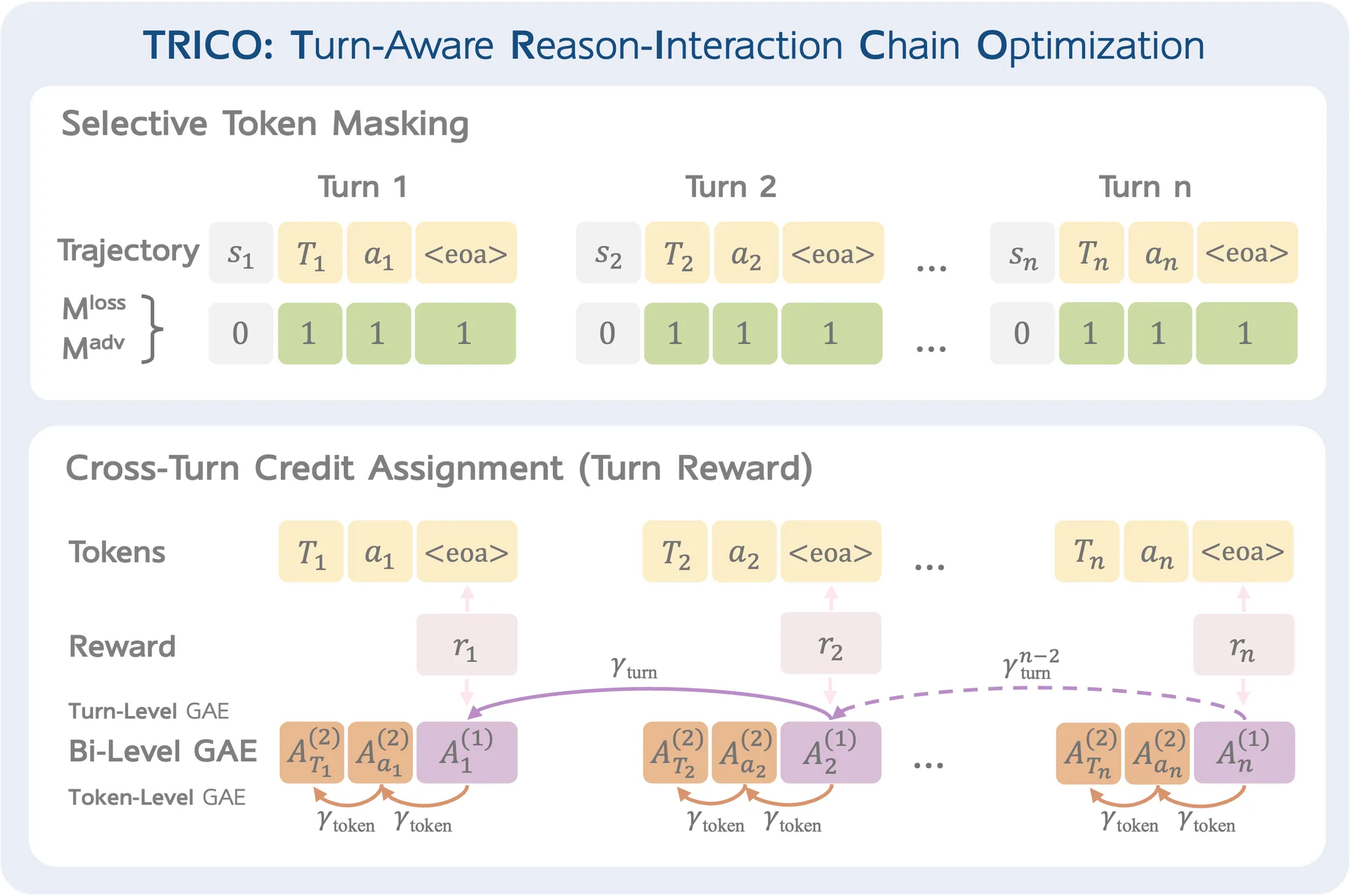
选择性Token掩码
TRICO引入了两种掩码机制,将优化重点放在交互轮次内 对动作至关重要的token上:
- $M^{loss}$:损失掩码,用于识别在策略优化过程中需要更新的 token
- $M^{adv}$:优势掩码,用于确定哪些 token 需要包含在优势函数的计算中
对于 VLM agents 生成的每个 token,$M^{loss}$都设置为 1,而对于其他 token(例如视觉输入 token),则设置为 0。$M^{adv}$ 同理。
简单点说就是只优化agent输出的token。
跨轮次信用分配
RICO 采用的是轨迹级别的奖励,而 TRICO 引入了双层 GAE (bi-level GAE) 方法和轮次级别的奖励,为 RL 训练提供了更细粒度的奖励信号。
TRICO 引入了两个折扣因子用于双层 GAE 方法:
- $\gamma_{turn}$:轮次间的折扣因子。
- $\gamma_{token}$:同一轮次内的折扣因子。
这种双层结构使得在多轮视觉交互中能够进行更精确的信用分配,帮助模型更好地将其行动与不同时间尺度下的结果联系起来。
此外,轮次奖励在每个边界处应用,而不是仅在轨迹完成时应用,从而实现更细粒度的反馈信号。
举个例子说明。
- 轮次级奖励:假设第一步为“向右推箱子”,当这步执行完时,agent的输出文本处于<eoa>,即轮次的边界,根据实验设置,每步通常有 -0.1 的惩罚,如果格式正确有 +0.5 的奖励。所以 R1 可能 = -0.1 + 0.5 = +0.4。这个奖励 R1 在本轮结束时就应用了。
- 双层GAE:假设一个任务两步完成,即有两个轮次的输出与奖励(注意R2是轮次级奖励和最终奖励之和)。第二轮的token级奖励根据$\gamma_{token}$衰减,直到到达第一轮输出的<eoa>位置,而第一轮的奖励继续衰减则要在这个值的基础上先乘上$\gamma_{turn}$,然后再以$\gamma_{token}$衰减。

实验
实验设置
- 环境: [推箱子](https://github.com/mpSchrader/gym - sokoban) 环境的视觉版本。
- 奖励:
- 箱子推到目标位置:+1.0
- 所有箱子放置到位:+10.0
- 格式正确:+0.5
- 如果在当前步骤未成功,每步会受到 - 0.1的惩罚
- 评估指标:
- 得分:轨迹的累计奖励
- 成功率
- 模型配置:Qwen 2.5 VL - instruction 3B
训练设置
- Rollout阶段
- 采样概率(Top-p):0.95
- 温度(Temperature):0.7
- 最大轮数:3 # VLM智能体最多可以与环境进行3轮交互
- 每轮最大动作数:3 # 虽然VLM智能体在当前轮次可能提出多个动作,但只会提取其提议中的前3个动作。
- 最大响应token数:128
- 更新阶段
- $\gamma_{turn}$:0.95
- $\gamma_{token}$:1.0
发现
作者设计了一个仅实现掩码机制(损失掩码和GAE掩码)的TRICO版本,称为 AICO(以动作为中心的交互链优化)。AICO屏蔽除动作之外的所有token,将优化纯粹集中在模型动作上。作者将AICO、TRICO以及与TRICO排除轮次奖励或双层GAE的变体进行了比较:
- 移除轮次奖励会导致性能略有下降。
- 移除双层GAE会导致模型在训练到一定程度后崩溃。
- AICO 在整体性能上大幅优于 TRICO(这可能与 Sokoban 任务的规模有关),但TRICO在难题上表现更好,而AICO 在解决简单的单步和两步问题上更稳定。TRICO 可能增强了 agent 的探索能力。
局限性与展望
局限性:
- 训练不稳定
- 选择性token掩码和跨轮次信用分配的作用的进一步思考
未来的工作方向:
- 将评估扩展到更多样化的环境,包括 GUI agents 和具身 agents 等需要复杂视觉推理的真实世界应用。
- 适配更大的模型
- 迁移到纯文本环境
- 尝试与视觉处理机制有更强联系的算法