原文链接:1511.04636
简介
在很多现实世界的决策任务中,状态和可能的动作都以自然语言的形式呈现,例如人机对话系统、辅导系统或文本冒险游戏。传统的强化学习方法往往难以处理这种大规模、甚至是潜在无限的自然语言状态和动作空间。特别是对于文本冒险游戏,玩家需要理解文本描述的游戏状态和一系列可能的动作文本,然后选择最佳动作以最大化长期回报。传统的基于表格或依赖于固定、已知动作集的深度Q网络(DQN)架构在这种情况下变得不切实际。
为了解决这一挑战,本文提出了一种新颖的深度神经网络架构,称为深度强化相关网络(Deep Reinforcement Relevance Network, DRRN)。DRRN 的核心思想是使用独立的深度神经网络分别处理状态文本和动作文本,并将它们映射到单独的embedding向量空间。通过一个交互函数结合这些embedding向量来近似强化学习中的 Q 函数,从而衡量状态和动作之间的“相关性”。这种架构能够有效地处理由自然语言描述的、潜在无限的离散动作空间。本文的主要贡献在于提出了这种独特的架构,并在实验中展示了它在文本游戏上的优越性能以及对措辞不同的动作描述的泛化能力。
方法:深度强化相关网络 (DRRN)
本文聚焦于处理状态和动作都由自然语言描述的顺序决策任务。对于自然语言描述的动作,动作空间理论上是无限的,且在文本游戏中,特定状态下的可行动作集通常是未知的子集,并且会随时间变化。
为了应对这一挑战,本文提出了 DRRN 架构。它与现有方法(如 Max-action DQN 和 Per-action DQN)的关键区别在于,DRRN 不将状态和动作简单地连接起来作为单个网络的输入,也不依赖于固定数量的输出。
文本环境建模
在每个时间步$t$,智能体将接收描述状态$s_t$ 的文本字符串(即 “状态文本”)和描述所有潜在动作$a_t$的若干文本字符串(即 “动作文本”)。其中$a_t \in \mathcal{A}_{t}$,$\mathcal{A}_{t}$ 是状态$s_t$下的可行动作集合,$\mathcal{A}_t \subseteq \mathcal{A}$,$\mathcal{A}$则是完成的动作空间。在许多文本游戏中,每个时刻$t$的可行动作集$\mathcal{A}_{t}$ 是未知的、随时间变化的。
DRRN 架构
DRRN 由一对独立的深度神经网络组成:一个用于状态文本embedding,另一个用于动作文本embedding。
- 独立的embedding网络: 鉴于状态文本(通常描述场景,可能较长且包含复杂结构)和动作文本(通常描述意图,可能简洁)的性质可能非常不同,使用两个独立的网络来学习它们的表示是更合适的。
- 文本到embedding: 对于任何给定的状态文本 $s_t$ 和可行动作列表中的某个动作文本 $a_t^i$,DRRN 首先使用对应的 DNN 将它们分别映射到各自的embedding向量空间。设 $h_{L,s}$ 是状态网络的最后一层隐藏层输出(状态embedding),$h_{L,a}^i$ 是动作网络对于动作 $a_t^i$ 的最后一层隐藏层输出(动作embedding)。
- 交互函数: 接着,使用一个通用的交互函数 $g(\cdot)$ 来结合状态embedding $h_{L,s}$ 和动作embedding $h_{L,a}^i$,以此近似状态-动作对 $(s_t, a_t^i)$ 的 Q 值:$Q(s, a^i; \Theta) = g(h_{L,s}, h_{L,a}^i)$。这个交互函数可以是内积、双线性运算,甚至是另一个非线性深度神经网络。内积是实验中常用的简化形式。通过这种方式,DRRN 为每个状态-动作对计算一个 Q 值,而不依赖于固定的动作数量。
- 动作选择: 在给定状态 $s_t$ 下,最优动作 $a_t$ 被选为使得 Q 值最高的动作:$a_t = \arg \max_{a_t^i} Q(s_t, a_t^i)$。在学习阶段,本文采用 Softmax 选择策略进行探索,根据 Q 值计算每个可行动作的概率来选择动作。
作为对比,我们看一下在DRRN之前的工作是如何做的:
- Max-action DQN将状态和所有的动作向量被连接作为输入,并输出所有动作对应的$Q$值。因此Max-action只能处理$|\mathcal{A}_t|$的最大数量已知的问题。
- Per-action DQN以状态 - 动作对作为输入,并为每个可能的动作输出单个 Q 值。
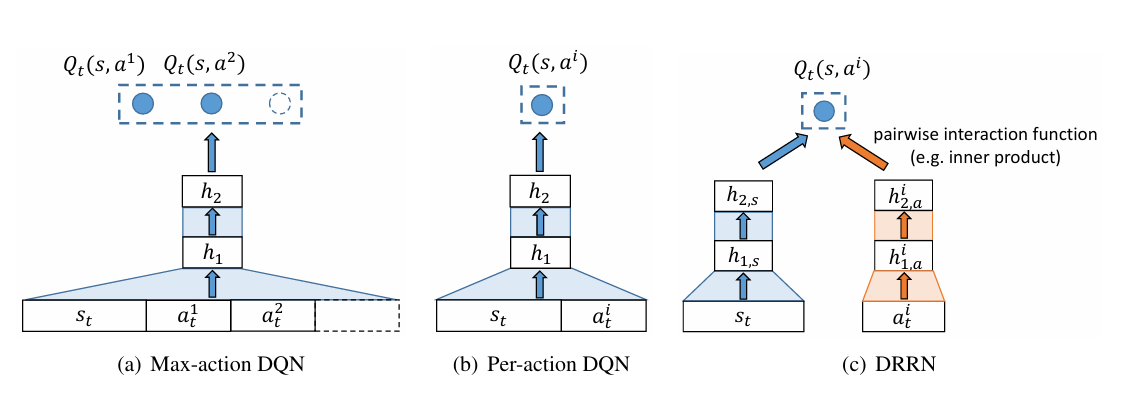
DRRN 学习过程
DRRN 的学习通过 Q-learning 算法实现,并结合了经验回放(experience-replay)策略。
- 经验收集: 使用 Softmax 选择策略与环境互动,收集一系列transition数据 $(s_k, a_k, r_k, s_{k+1})$,并存储在经验回放记忆库中。
- Mini-batch采样: 从记忆库中随机采样一个迷你批量的过渡元组。随机采样打乱了经验的顺序,有助于提高学习稳定性。
- 目标 Q 值计算: 对于每个采样的元组 $(s_k, a_k, r_k, s_{k+1})$,计算目标 Q 值 $y_k$。如果 $s_{k+1}$ 是终止状态,目标 Q 值就是即时回报 $r_k$;否则,目标 Q 值是即时回报 $r_k$ 加上折扣因子 $\gamma$ 乘以在状态 $s_{k+1}$ 下所有可能动作的最大 Q 值:$y_k = r_k + \gamma \max_{a' \in A_{k+1}} Q(s_{k+1}, a'; \Theta^-)$。这里 $\Theta^-$ 是目标网络的参数,通常是主网络参数的延迟复制。
- 参数更新: 使用梯度下降法更新网络参数 $\Theta$,以最小化预测 Q 值 $Q(s_k, a_k; \Theta)$ 与目标 Q 值 $y_k$ 之间的平方误差 $(y_k - Q(s_k, a_k; \Theta))^2$。虽然批量中包含多个可能的动作,但反向传播只针对实际采取的动作 $a_k$ 进行。由于动作侧网络参数是共享的,这有效地更新了与所有动作相关的模型。
- 端到端学习: 整个网络(包括状态embedding网络、动作embedding网络和交互函数)是端到端学习的。通过从回报信号中学习,状态文本和动作文本的表示向量会自动在embedding空间中对齐,使得“好”或“相关”的动作文本与状态文本的交互函数输出更高,而“坏”或“不相关”的动作文本的输出较低。
通过这种架构,DRRN 能够学习到自然语言动作空间的连续表示,并度量状态与动作文本之间的相关性,从而解决自然语言动作空间带来的挑战。
以下展示了DRRN的算法流程:

实验
实验设置
常见的文本游戏类型有如下三种:
(a) 基于解析器的游戏(Parser-based)
- 交互方式:玩家输入自然语言指令(如动词短语),例如 “eat apple”(吃苹果)、“get key”(拿钥匙)、“go east”(向东走)。
- 动作空间:由解析器预定义的固定指令集,语言结构较为简单。
(b) 选择型游戏(Choice-based)
- 交互方式:状态文本中嵌入可点击的动作选项,玩家从预设的离散选项中选择(如 “Look up”(抬头看)或 “Ignore the alarm”(忽略警报))。
- 动作空间:动作是状态文本的显式子集,选项数量有限且随状态变化,无需玩家主动输入指令。
(c) 超文本游戏(Hypertext-based)
- 交互方式:动作以超文本链接形式嵌入状态文本,玩家点击链接触发剧情分支(如网页中的可点击文本)。
- 动作空间:动作与状态文本高度融合,可能包含复杂句子或上下文相关选项,例如状态文本中的某个名词或短语作为可交互元素。

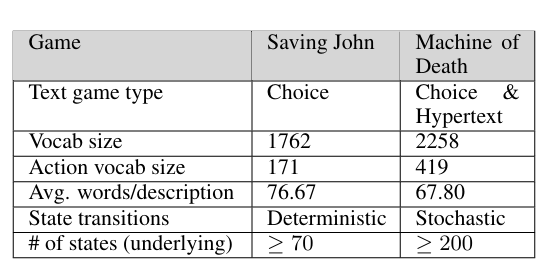
本文在两个文本冒险游戏上评估了 DRRN 的性能:“拯救约翰”(Saving John,确定性,选择式)和“死亡机器”(Machine of Death,随机性,选择/超文本式)。这些游戏在词汇量、描述长度和状态转换特性上有所不同:
本文比较了 DRRN 与线性模型、Max-action DQN 和 Per-action DQN 等基线的性能。所有方法都使用 Q-learning 框架进行训练,并采用经验回放和 Softmax 选择策略。为了鼓励模型理解文本而不是记忆动作顺序,本文在提供给模型的可行动作列表时会随机打乱它们的顺序。
实验现象与结论
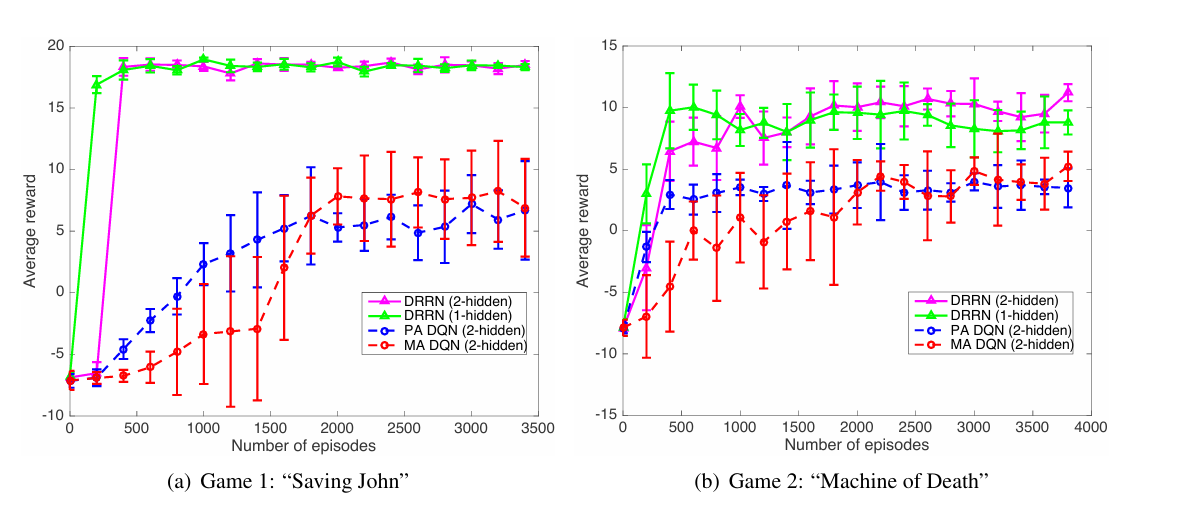
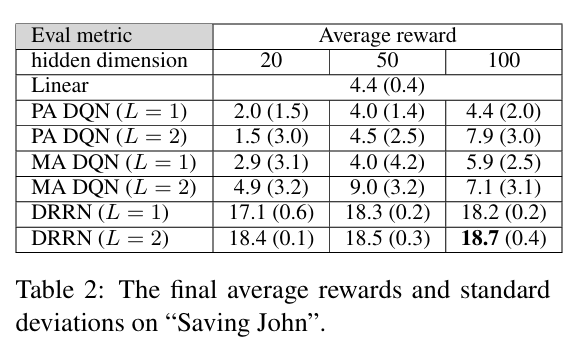
- 学习效率和最终性能: 学习曲线表明,与基线模型相比,DRRN 收敛速度更快,并且达到了更高的平均回报。最终性能统计表也一致地表明,DRRN 在不同隐藏层维度配置下都优于所有基线,且方差通常更低。这支持了本文的假设,即 DRRN 的架构更适合捕获状态文本和动作文本之间的相关性。两层隐藏层的模型通常比单层表现更好,但收敛速度可能稍慢。
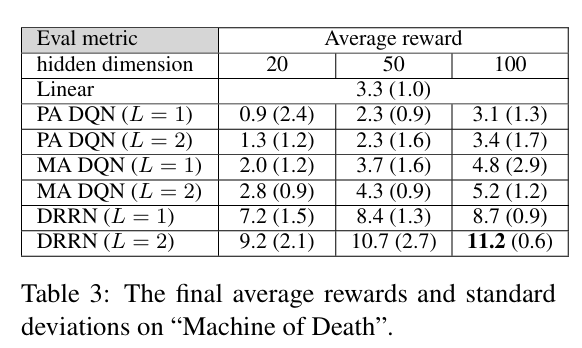
- 交互函数: 实验表明,双线性运算作为交互函数的效果与内积相似,而将状态和动作embedding向量简单拼接后输入到另一个 DNN 的方式则会导致性能下降。
- 泛化到措辞不同的动作: 为了测试模型对“未见过”的动作描述的泛化能力,作者请人对“死亡机器”游戏中的部分动作进行了改写。然后使用在原始动作描述上训练好的 DRRN 模型预测这些改写后动作的 Q 值。
- 结果显示,原始动作的 Q 值与相应改写后动作的 Q 值之间存在很强的正相关性 ($PR^2$ = 0.95)。
- 下图展示了 DRRN 能够预测导致良好结局的动作具有较高的 Q 值,即使这些动作的描述与训练时见过的原始描述不同,或者甚至是凭空创造的但在语义上相关的动作。
- 直接在改写后的动作描述上测试用原始动作训练的模型,DRRN 的平均回报虽然略低于在原始动作上的表现,但显著优于所有基线模型。
- 这些发现强有力地支持了 DRRN 提取文本含义而非简单记忆字符串的能力,并且能够有效泛化到措辞不同的自然语言动作描述。
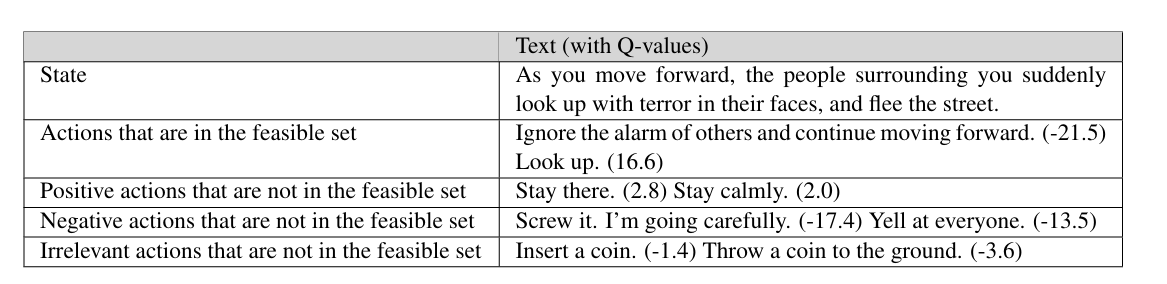
- 连续表示: 尽管动作空间是离散的,DRRN 学习了其连续表示。如改写实验所示,这种连续空间表示具有良好的泛化能力。
结论
深度强化相关网络(DRRN)是一种针对处理具有自然语言状态和动作空间的决策任务而设计的有效架构。通过使用独立的深度神经网络为状态和动作学习embedding表示,并通过交互函数衡量它们的相关性来近似 Q 函数,DRRN 能够更好地捕捉状态与动作之间的关联,并在文本游戏任务上实现了更快的收敛速度和更高的性能。特别是,DRRN 展现了对措辞不同的自然语言动作描述的良好泛化能力,这证明了其对文本含义的捕捉能力。