原文链接:2010.02903
简介
文字冒险游戏为自主智能体带来了独特的挑战,它们需要在自然语言环境中运行,并且处理极其庞大的动作空间。在任何给定的游戏状态下,只有极少一部分的动作命令是可执行的(admissible)。例如,在客厅里,如果一扇门被钉死了,智能体可能倾向于尝试“move rug”而不是“knock on door”。然而,即使是目前最先进的游戏智能体,也通常不包含这种语言先验知识,而是依赖于规则启发式方法或学习环境提供的便利(如可执行动作列表)来规避这些问题。
为了解决这一挑战,本文提出了 CALM(Contextual Action Language Model,上下文动作语言模型)。核心思想是训练语言模型来捕捉人类游戏玩法中的语言先验和一般游戏常识,从而在每个游戏状态下生成一个动作候选集。作者构建了一个包含 590 种不同文字游戏的 426 份人类游戏记录的新数据集来训练 CALM。随后,他们将 CALM 与一个强化学习智能体DRRN相结合,由 RL 智能体对 CALM 生成的动作候选进行重排序,以最大化游戏中的奖励。
一句话总结:CALM预训练了一个动作生成语言模型(模型为GPT2),每次会生成top-k个动作给DRRN,本质上是利用语言知识减少文字游戏巨大的动作空间。
方法
文字冒险游戏可以形式化为一个部分可观察马尔可夫决策过程(POMDP)。玩家发出文本动作 $a \in A$,并收到文本观察 $o \in O$ 和标量奖励 $r \in R$。潜在状态$s \in S$包含当前游戏信息(如玩家和物品的位置、玩家的物品栏),这些信息仅部分反映在观察$o$中。转移函数$s^{\prime}=T(s,a)$规定了动作$a$如何作用于状态$s$,当时$T(s,a)\neq s$(即动作可被游戏解析并改变状态),动作a在状态s下是可行的。玩家无法获取状态$S$、转移函数$T$和奖励函数$R$。
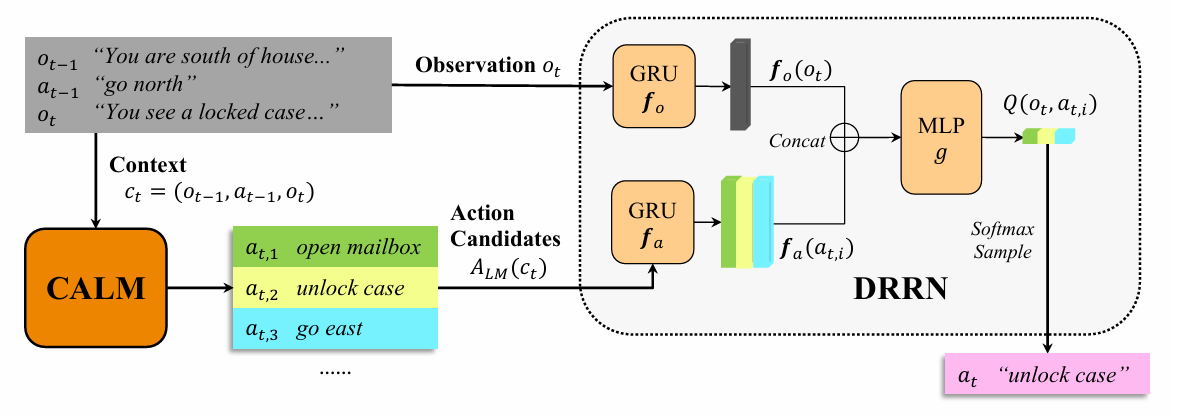
CALM
为了减小巨大的动作空间并使学习可行,CALM 的目标是训练语言模型来生成紧凑的动作候选集。
训练数据
CALM 使用从 ClubFloyd 抓取的 426 份人类游戏记录,涵盖 590 款游戏。这些记录虽然可能有噪音且动作不总是最优,但包含了丰富的语言先验和游戏常识。数据集包含 223,527 个上下文-动作对。为了测试模型的泛化能力,用于评估的 28 款 Jericho 游戏的记录不用于训练 CALM。
训练目标
在时间步 $t$,上下文 $c_t$ 定义为之前的观察和动作的历史$(o_1, a_1, ..., a_{t-1}, o_t)$。在实践中,发现使用大小为 2 的窗口效果良好,即 $c_t = (o_{t-1}, a_{t-1}, o_t)$。
CALM 训练一个参数化的语言模型 $p_{\theta}(a|c)$来生成动作 $a$,其中 $c$是上下文。训练目标是最小化所有人类游戏记录上的交叉熵损失:
由于动作 $a$ 通常是多词短语,损失函数可以进一步分解为每个 token 的交叉熵之和:
$$p_\theta(a|c)=\prod_{i=1}^mp_\theta(a^i|a^{\mathrel{<}i},c)$$模型
研究中探索了两种类型的语言模型进行训练:
- n-gram 模型
- GPT-2 模型: 使用一个在 WebText 语料库上预训练过的 GPT-2 模型,并在 ClubFloyd 数据集上根据上述交叉熵损失进行微调。相比n-gram 模型,GPT-2 能够以更灵活的方式建模上下文和动作之间的依赖关系,对动作结构假设较少。
DRRN回顾
DRRN(Deep Reinforcement Relevance Network) 是一种RL算法,学习一个参数化的 Q 网络 $Q_{\phi}(o, a)$。它使用两个独立的编码器 $f_o$ 和 $f_a$ 分别编码观察 $o$ 和每个动作候选 $a$ (通常使用 RNN 如 GRU),然后通过一个解码器 $g$ 聚合表示来得出 Q 值 $Q_{\phi}(o, a) = g(f_o(o), f_a(a))$。通过最小化时序差分 (TD) 损失来学习参数 $φ$。在游戏过程中,使用 softmax 探索策略来采样动作。注意,尽管上述公式仅包含单个观察,但也可以将其扩展为基于更长上下文$c=(o_1,a_1,…,o_t$)(截至当前时间步t的先前观察和动作)的策略$\pi_(a|c)$。
结合RL
CALM 生成 top-k 个动作候选$A_{\text{LM}}(c, k) \subset A$为 RL 智能体缩小动作空间,从而训练一个 DRRN 来学习在这个缩减动作空间上的 Q 函数。以GPT2模型为例,CALM采用beam search获得这top-k个动作。对于DRRN,只需要将 Q 值计算和策略采样方程中完整动作空间 $A$ 替换为 $A_{\text{LM}}(c, k)$ 即可。
注意,CALM 在 RL 过程中不进行微调,这是为了保持其通用的语言先验以避免过拟合特定游戏。