原文链接:2503.06580
简介
偏向工程的一篇论文,通过三阶段SFT和两阶段RL实现了一个AutoCoA训练框架。
前置概念
Agent的发展
本文区分了以ReAct、Reflexion为代表的prompting-based Agent与以Deep Research为代表的learning-based Agent。前者称为Agentic Workflow,后者被称为Agent Model。核心区别就是Model是不需要事先做任务编排的,它是模型本身的能力。文中给出了两个发展脉络图,分别从模型的角度与交互范式的角度阐述了Agent Model与之前工作的区别。
从模型的角度:
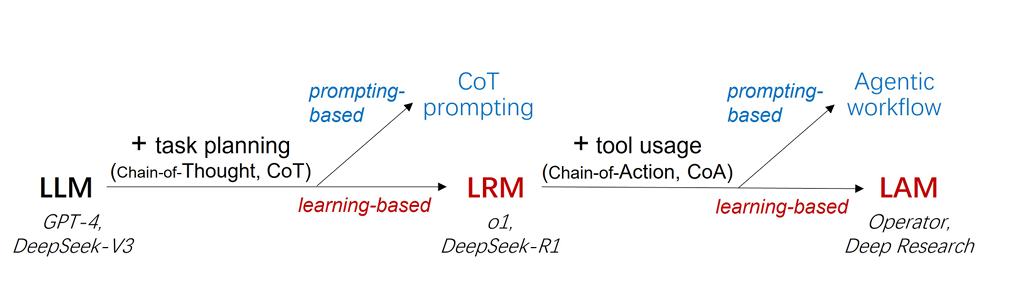
从交互范式的角度:
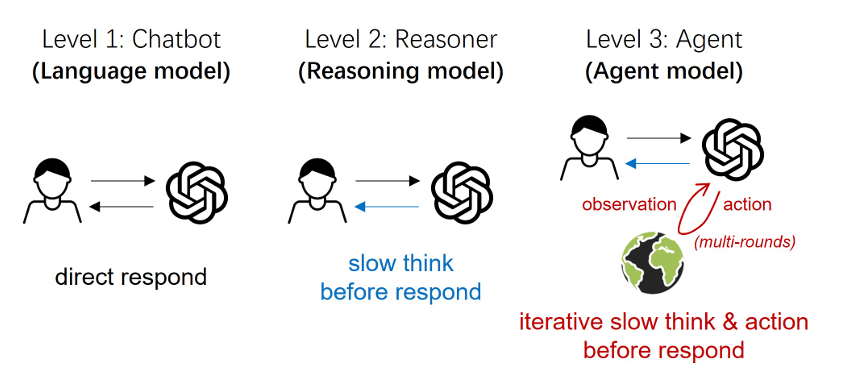
Agent Model的定义
文中给出的Agent Model的定义如下:
智能体模型是一种基于推理模型构建的生成模型,通过端到端的面向任务的工具增强训练得到强化。它生成推理(思维链)和行动(行动链)交错的步骤序列,其中每个行动会调用一种工具与外部环境进行交互。这些交互产生的观察结果会指导后续的推理和行动,直至任务完成。
Agent Model的数学建模
Agent Model的推理可以形式化为一个部分可观测马尔可夫决策过程(POMDP)。
其中状态被定义为$[s_{0}, tc, x_{1:n}]$,包括:
(1)$s_{0}$:初始环境状态(例如,数字或物理系统的状态);
(2)tc:任务上下文(例如,用户提示);
(3)$x_{1:n}$:到目前为止生成的序列,由模型生成的token和来自环境的响应组成。
动作则是生成下一个token $x_{n + 1} \sim \pi_{\theta}(\cdot | s_{0}, tc, x_{1:n})$,其中$\pi_{\theta}$是由$\theta$参数化的策略。
在每一步,$\pi_{\theta}$会生成如下类型的tokens:
- ⟨thinking⟩:产生一条思维链(CoT),思维链代表内部的思考或规划。在这个token之后,会生成一个推理序列$r=[r_{1}, r_{2}, ..., r_{k}]$,其中每个$r_{i}$都是推理过程中的一个token。
- ⟨action⟩:产生一条行动链(CoA),调用工具与环境进行交互。在这个标记之后,模型会在内部生成或从环境中获取:
- 动作类型:如"search"
- 动作参数:如具体的query
- 动作响应:获取环境的响应$o = \tau(p)$ ,类似于ReAct中的观察结果。响应会被追加到轨迹中,为后续轮次提供上下文信息。
- ⟨answer⟩:输出最终模型响应,表明任务已完成,或者因超出预定义的资源限制而终止。在这个token之后,会生成一个答案序列$a = [a_1, a_2, ..., a_m]$,代表任务的解决方案。
整个推理流程如下:

面临的挑战
- 平衡推理与行动。
- 风险:目前对LRM模型微调来增强行动能力的方式带来了可能遗忘了本来的CoT生成能力的风险
- 难点:如何让模型学会何时推理、何时行动
- 管理外部环境交互。
- 调用工具以及环境交互带来了训练的效率低下的同时也带来了更高昂的训练成本
- 外部环境动态性带来的训练不稳定。
方法:AutoCoA框架
AutoCoA包含两个阶段,SFT和RFT,通过多轮训练将CoA能力逐渐内化到模型中。
训练数据构造
采用DeepSeek-R1-Distill-Qwen-32B模型,在基于FlashRAG 构建的本地 wiki 搜索引擎进行采样。CoT和CoA数据采用不同的1万个样本,通过对应的prompt进行构建。
SFT阶段
SFT Stage 1:CoT + A
- 目标:学会何时行动。辨别包含⟨action⟩和不包含⟨action⟩的输出模式。
- 数据:构造$x_{chosen }$和$x_{reject}$,其中$x_{chosen}$数据大部分中包含⟨action⟩,少部分不包含⟨action⟩但是⟨answer⟩也是对的。这种数据用了1500对。
- 损失函数:
损失函数包含两部分,对比损失让模型倾向于输出正例,辅助监督损失防止正负例的概率均下降。注意$c$为上下文。- 对比损失 $$L_{contra }=-\log \sigma\left[P\left(x_{chosen } | c\right)-P\left(x_{rejected } | c\right)\right]$$
- 辅助监督损失
SFT Stage 2:CoT + CoA(w/ Observation Mask)
- 目标:学会如何行动。
- 数据:混合使用5,000个CoA数据和1,000个CoT数据。
- 损失函数: 在计算损失时屏蔽环境响应token,专注于学习动作类型和动作参数的生成。 其中$I_{x_{i} \neq o}$表示不是外部反馈的token。
SFT Stage 3: CoT + CoA (w/o Observation Mask)
- 目标:学习隐式世界模型。
- 数据:同stage 2
- 方法:去掉环境响应token的屏蔽mask,相当于把环境响应也做了预测,可以看成是学习了一个隐式的世界模型。
RFT阶段
本阶段训练,算法采用GRPO,奖励采用精确匹配奖励和格式遵循奖励。
- Exact matching reward:仅当最终输出与真实结果完全匹配时才给予正奖励。
- Format penalty:如果模型的输出不遵循所需格式,例如缺少像
⟨think⟩这样的关键标签,则会施加惩罚。
RL Stage 1: CoT + CoA (Simulated Environment)
- 目标:在模拟环境中进行广泛探索。
- 方法:用SFT模型作为环境,生成模拟的环境响应
RL Stage 2: CoT + CoA (Real Environment)
- 目标:适应真实世界环境。
- 方法:在真实环境训练
实验结论
- 直接做RL提升有限,SFT作用显著。
- 直接在真实世界中训练提升有限,模拟环境中的训练至关重要。
- 学习CoA与否影响最大的是需要多次动作的任务。